Tag: bitcoin_ml

Fine-Tuning Foundation Models - When Transfer Learning Works
by
Jerome Etienne
on
Wed Jun 17 2026
Encoder-only fine-tuning of Chronos-2-small on 4.7 years of Bitcoin history, with proper checkpoint restoration, finally produces a deep-learning win - but only under all three conditions, and only when read through a 5-seed confidence interval rather than a lucky single seed. The honest bottom line and what it costs to get there.
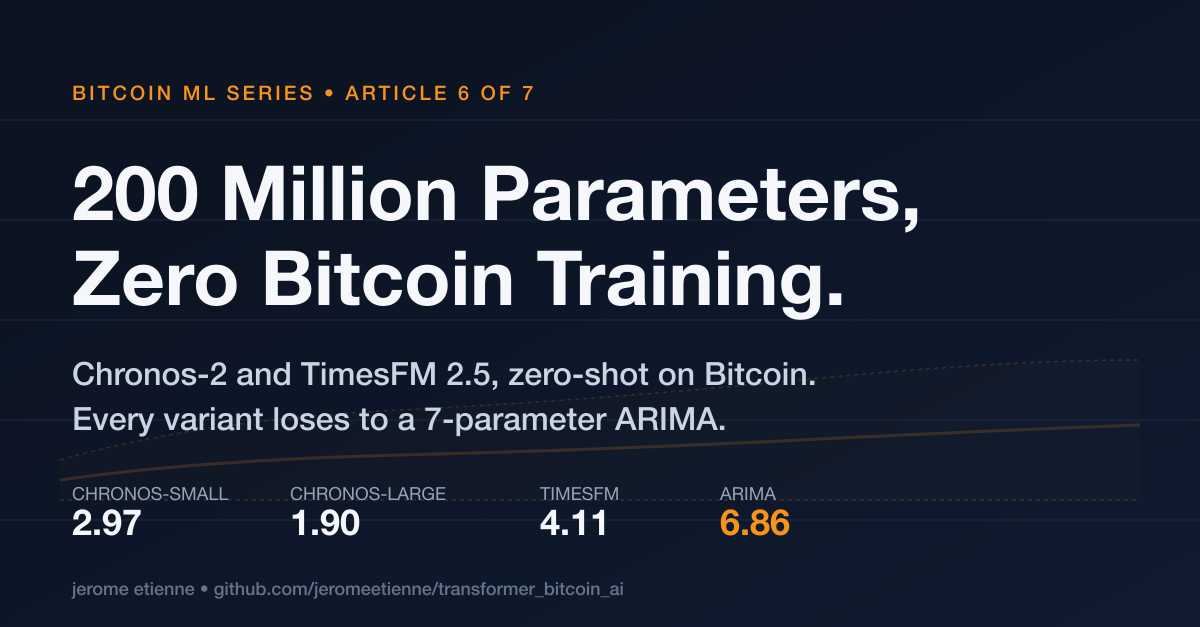
When a Model Trained on Everything Fails on Bitcoin
by
Jerome Etienne
on
Mon Jun 15 2026
Zero-shot Chronos-2 (28M/120M) and TimesFM 2.5 (200M) on Bitcoin without a single weight update. The pretrained prior - built on hundreds of millions of time series from every domain - loses to a 7-parameter ARIMA on every metric. A concrete look at where transfer learning quietly breaks.
When Attention Fails - The Transformer That Couldn't
by
Jerome Etienne
on
Wed Jun 10 2026
The Temporal Fusion Transformer brings attention, variable selection, and gated residuals to the problem - and posts the worst Sharpe of any trained model. The post argues that on a near-random-walk signal with limited data, architectural sophistication is a liability, not an asset.

The First Deep Learning Failure - Why LSTMs Lose on This Data
by
Jerome Etienne
on
Mon Jun 08 2026
Two stacked LSTM layers, thousands of parameters, 1,448 training bars - and directional accuracy comes in below a coin flip. The post walks through the architecture, the sweep results (smaller is better), and the structural reason the model fits noise instead of signal.

When 31 Features Lose to 3 Parameters - The XGBoost Lesson
by
Jerome Etienne
on
Wed Jun 03 2026
Gradient boosting on 31 engineered features (lagged returns, rolling volatility, OHLC summaries) loses on point error but wins on trading return and Sharpe. A clean illustration that magnitude calibration and directional confidence can beat raw accuracy in a trending regime.

How Classical Statistics Beats the Naive Model (By $1.20)
by
Jerome Etienne
on
Mon Jun 01 2026
ARIMA with three to seven parameters on differenced prices, fit on the same Bitcoin slice. The win on MAE is razor-thin, but the directional accuracy and Sharpe tell a different story - and the order sweep reveals that in-sample selection criteria don't rank out-of-sample trading metrics.

The Dumbest Possible Bitcoin Predictor (And Why It Matters)
by
Jerome Etienne
on
Wed May 27 2026
The naive last-value model - zero parameters, predicts the next bar equals the current bar - sets the floor every later model has to clear. This post explains why a model with no learning is the load-bearing benchmark for the rest of the series.

Can Machine Learning Predict Bitcoin? Seven Models, One Honest Answer
by
Jerome Etienne
on
Mon May 25 2026
Series opener for a 7-model experiment on Bitcoin 4-hour forecasting. Lays out the data, the test window, the metric stack (MAE/RMSE/MAPE/directional accuracy/Sharpe), the evaluation philosophy, and previews the recurring lessons that surface across the ladder from naive baseline to fine-tuned foundation model.